
관리 메뉴

FireDrago
[JPA] JPQL 기본문법 2 본문
<경로 표현식>
점을 찍어 객체 그래프를 탐색하는 것
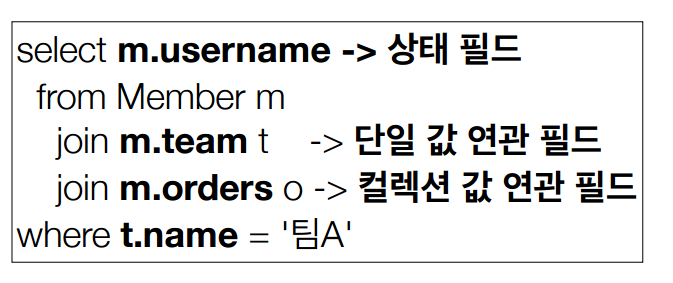
| 상태필드 | 상태필드 | - 단순히 값을 저장하기 위한 필드 |
| 연관필드 | 단일 값 연관필드 | - @ManyToOne, @OneToMany 대상이 엔티티 - 묵시적 내부조인 발생 -> 명시적 조인을 사용하자 |
| 컬렉션 값 연관필드 | - @OneToMany, @ManyToMany 대상이 컬렉션 - 묵시적 내부조인 발생 -> 명시적 조인을 사용 - FROM 절에서 명시적 조인을 통해 별칭을 얻으면 별칭을 통해 탐색 가능 |
// 단일 값 연관경로 탐색 -> 묵시적 조인 발생
String query = "select m.team From Member m";
// 명시적 조인으로 조인 사용을 쿼리에 표시하자
String query = "select m from Member m join m.team t";
List<Team> result = em.createQuery(query, Team.class)
.getResultList();
-----------------------------------------------------------
Hibernate:
/* select
m.team
From
Member m */ select
t1_0.id,
t1_0.name
from
Member m1_0
join
Team t1_0
on t1_0.id=m1_0.TEAM_ID// 컬렉션 값 연관경로 탐색도 명시적 조인을 사용하자
String query = "select m From Team t join t.members m";
List<Collection> result = em.createQuery(query, Collection.class)
.getResultList();
------------------------------------------------------------------
Hibernate:
/* select
m
From
Team t
join
t.members m */ select
m1_0.id,
m1_0.age,
m1_0.memberType,
t1_0.id,
t1_0.name,
m1_0.username
from
Team t1_0
join
Member m1_0
on t1_0.id=m1_0.TEAM_ID<페치 조인 (fetch join)>
JPQL 에서 성능 최적화를 위해 제공하는 기능으로, 연관된 엔티티나 컬렉션을 SQL 한번에 함께 조회하는 기능이다.
한가지 의문이 생긴다. 페치조인으로 즉시로딩 할건데 왜 굳이 지연로딩을 사용해야 하는 것일까?
상황에 따른 최적화가 가능해지기 때문이다. 기본 설정은 지연로딩으로 사용하되, 필요할때만 페치조인을 사용하여
N+1 문제 같은 쿼리가 여러번 실행되는 것을 방지할 수 있다.
-------------------- 일반 조인 ---------------------------------
SELECT m
From m INNER JOIN m.team t
-- 실행 SQL
SELECT
M.ID,
M.AGE,
M.TEAM_ID,
M.NAME,
FROM
MEMBER M INNER JOIN TEAM T ON M.TEAM_ID = T.ID
-- Member 엔티티의 내용만 가져온다. 조인된 테이블의 내용은 가져오지 않는다.
--------------------- 페치 조인 --------------------------------
SELECT m
FROM Member m JOIN FETCH m.team
-- 실행 SQL
SELECT
M.*, T.*
FROM
MEMBER M INNER JOIN TEAM T ON M.TEAM_ID = T.ID
-- 조인된 테이블의 컬럼내용도 가져온다. => TEAM 엔티티의 내용도 가져온다.
-- 기본적으로 지연로딩을 쓰지만 SQL이 너무 많이 나갈경우 페치 조인을 고려한다.
<Named 쿼리>
미리 쿼리를 정의하고 이름을 부여하여 필요할 때 사용할 수 있다.
한번 정의하면 변경할 수 없는 정적인 쿼리이다. 에플리케이션 로딩 시점에 JPQL 문법을 체크하기 때문에
컴파일 단계에서 오류를 확인 할 수 있고, 쿼리를 재사용 할 수 있어서 성능상의 이점이 있다.
// NamedQuery 설정
@Entity
@NamedQuery (
// 쿼리명은 '클래스명.메서드명' 관례
name = "Member.findByUsername",
query = "select m from Member m where m.username = :username")
public Class Member {
...
}
//NamedQuery 사용시
List<Member> resultList =
em.createNamedQuery("Member.findByUsername", Member.class)
.setParameter("username", "corn")
.getResultList();
// 다중 NamedQuery 설정
@Entity
@NamedQueries({
@NamedQuery (
name = "Member.findByUsername",
query = "select m from Member m where m.username = :username"
),
@NamedQuery (
name = "Member.findByTeamId",
query = "select m from Member m where m.teamId = :teamId"
)
})
public Class Member {
...
}'프로그래밍 > JPA' 카테고리의 다른 글
| [JPA] cascade는 언제 사용해야 할까? (0) | 2024.04.09 |
|---|---|
| [JPA] @PersistenceContext 사용해야 하는 이유 (0) | 2024.04.08 |
| [JPA] JPQL 기본문법 1 (0) | 2024.04.04 |
| [JPA] 연관관계 관리 (0) | 2024.04.01 |
| [JPA] 엔티티 매핑 (0) | 2024.03.27 |
'프로그래밍/JPA' Related Articles
more

